


High quality product data is one of the key factors that will determine the success of your PIM implementation. But how do you know if the quality of your data is good or bad? In this blog post, we outline the six important dimensions to assess your data quality
.tb_button {padding:1px;cursor:pointer;border-right: 1px solid #8b8b8b;border-left: 1px solid #FFF;border-bottom: 1px solid #fff;}.tb_button.hover {borer:2px outset #def; background-color: #f8f8f8 !important;}.ws_toolbar {z-index:100000} .ws_toolbar .ws_tb_btn {cursor:pointer;border:1px solid #555;padding:3px} .tb_highlight{background-color:yellow} .tb_hide {visibility:hidden} .ws_toolbar img {padding:2px;margin:0px}

For any product business, high-quality product data is a critical success factor, and poor data a big deterrent to growth. To achieve high data quality, you need to define and enforce it uniformly across the board.
Often people, and organizations, mistake large volumes of data for good quality data. More is not always better; only good quality is truly better. But what does good quality mean? Who knows the standards and who upholds it?
In this post — fourth in the series on PIM — we delve deeper into data cleaning exercise by pursuing the question of data quality.
.tb_button {padding:1px;cursor:pointer;border-right: 1px solid #8b8b8b;border-left: 1px solid #FFF;border-bottom: 1px solid #fff;}.tb_button.hover {borer:2px outset #def; background-color: #f8f8f8 !important;}.ws_toolbar {z-index:100000} .ws_toolbar .ws_tb_btn {cursor:pointer;border:1px solid #555;padding:3px} .tb_highlight{background-color:yellow} .tb_hide {visibility:hidden} .ws_toolbar img {padding:2px;margin:0px}
The importance of a data quality framework
Data quality is not a unidimensional measure. Every product category has a different set of attributes, and different rules for distinguishing between the good, bad, and the ugly. So, each organization needs to build its own framework/system to measure data quality.
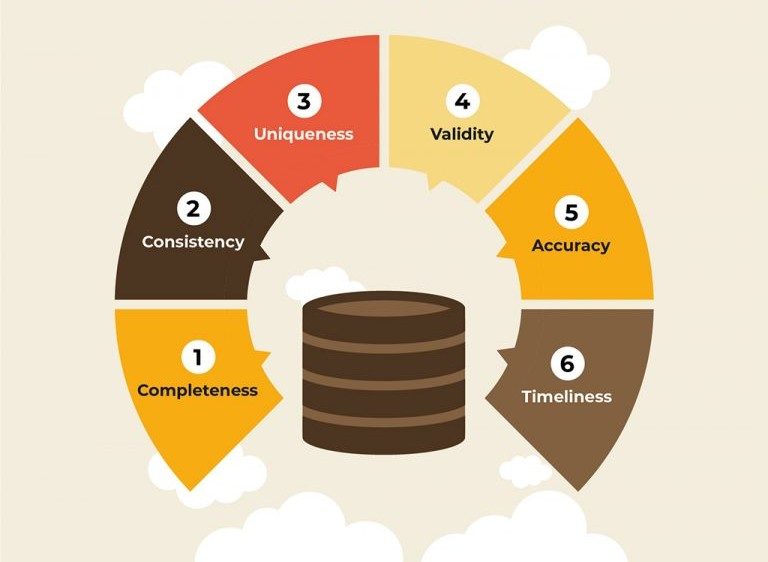
But there’s a lot of inspiration to choose from. It is possible to abstract some common dimensions of quality for data — which is what DAMA (Data Management Association) UK has done. Here’s a look at the core quality dimensions, as defined by DAMA.
.tb_button {padding:1px;cursor:pointer;border-right: 1px solid #8b8b8b;border-left: 1px solid #FFF;border-bottom: 1px solid #fff;}.tb_button.hover {borer:2px outset #def; background-color: #f8f8f8 !important;}.ws_toolbar {z-index:100000} .ws_toolbar .ws_tb_btn {cursor:pointer;border:1px solid #555;padding:3px} .tb_highlight{background-color:yellow} .tb_hide {visibility:hidden} .ws_toolbar img {padding:2px;margin:0px}
.tb_button {padding:1px;cursor:pointer;border-right: 1px solid #8b8b8b;border-left: 1px solid #FFF;border-bottom: 1px solid #fff;}.tb_button.hover {borer:2px outset #def; background-color: #f8f8f8 !important;}.ws_toolbar {z-index:100000} .ws_toolbar .ws_tb_btn {cursor:pointer;border:1px solid #555;padding:3px} .tb_highlight{background-color:yellow} .tb_hide {visibility:hidden} .ws_toolbar img {padding:2px;margin:0px}
The 6 fundamental data quality dimensions
1. Is your data complete?
Completeness is a measure of how much data you have as opposed to how much is needed to make it comprehensive.
Assume that there are 8 data attributes to a shirt — length of sleeves, colour, material, fit, size range, wash instructions, pattern, and style. A shirt that has data about the first six attributes, but is missing pattern and style information, has a completeness score of 75%. Completeness of product data is important because it increases the likelihood of conversion. What’s more, incomplete data can affect search filters and product discoverability on your online platforms.
However, not every product attribute needs to score a 100% on completeness. For example, it is impossible for a shopper to buy a shirt online without knowing its size, but he could possibly make a choice without knowing what the pattern is called. Hence, you will need to set thoughtful benchmarks for different product attributes and families.
2. Is your data consistent?
Consistency is defined as the absence of a difference, when comparing two or more instances of an attribute.
In the above example, if a shirt’s pattern data is to be found in two places — on the product webpage and in the packaging of the shirt itself — is the information identical across both?
Maintaining consistency is important, since consumers expect to receive the exact product they ordered. So, even if the web page and the product packaging have two different ways to describe the same information, the customer is left confused at best, suspicious and disgruntled at worst.
You can set data quality standards for consistency depending on how critical particular attributes are to the product and its sales.
3. Is your data unique?
Uniqueness is a measure of the number of things in the ‘real world’ compared to the number of records of things in the data set.
If a shirt is available in five prints, does the website show five instances of the shirt — or does it show six or seven? That is, have duplicates crept into your database? Duplicate data may have many causes — data entry and programming errors, system migration errors, etc. — but the effect is always to baffle systems, employees, and customers, with consequences ranging from harmless to dire. It could also confuse search engines and affect your product’s search results.
Set a very stringent benchmark for this dimension, to ensure that all duplicates are weeded out.
4. Is your data valid?
he validity of your data is a measure of how much it conforms to the syntax (format, type, range) of its definition.
For example, ‘blue’ is an acceptable value for the color attribute of a shirt, but not a valid value for the style attribute. Validity can also mean conforming to public standards for product information — for example, mentioning the shirt’s dimensions in inches rather than centimeters, and sizes according to American standards rather than European.
While validity is important throughout your data set, if a particular attribute has a very high value to business, then you may want to set a more rigorous rule for it.
5. Is your data accurate?
Accuracy is the degree to which data correctly describes and mirrors the ‘real world’ object being described.
For a shirt in a catalogue, below are some questions you can ask to assess the accuracy of information.
Is the shirt actually made from 100% cotton, as described?
Is the claim that the shirt does not shrink during wash validated?
Are there any incorrect spellings of products or patterns?
Errors in certain high-visibility product attributes can affect sales and user experience more than others. However, customers assume that every piece of information in your catalogue is true and any deviation can hinder trust in your brand and products.
It would be wise to have high standards of accuracy across all your product data.
6. Is your data timely?
Timeliness is the degree to which your data represents reality from the required point in time.
If your data reflects the state of your product accurately, without delay, at all times, it can be said to be timely. The timeliness you will need to maintain can depend on user expectations. For example, if there is a change to the price or stock situation of your shirt, your online customer would expect to know about it immediately. While, if you have introduced a new pattern of shirt in your summer collection, a slight delay could be tolerated between your offline launch and your online launch.
Have a sharp customer-focus while setting standards for this data quality dimensions, what’s not acceptable to the customer should not be acceptable to you.
Besides these six quality dimensions, you may also want to include other rules, depending on the type of your business — is the data you are revealing sensitive in nature, could it affect the sensibilities of any group of people, how much confidence do you have in your data, is it governed by a data governance policy, etc.
Once you have chalked out a set of rules for these data dimensions, it is time to apply them to your current product data — but that’s a post for another day! Stay tuned.
.tb_button {padding:1px;cursor:pointer;border-right: 1px solid #8b8b8b;border-left: 1px solid #FFF;border-bottom: 1px solid #fff;}.tb_button.hover {borer:2px outset #def; background-color: #f8f8f8 !important;}.ws_toolbar {z-index:100000} .ws_toolbar .ws_tb_btn {cursor:pointer;border:1px solid #555;padding:3px} .tb_highlight{background-color:yellow} .tb_hide {visibility:hidden} .ws_toolbar img {padding:2px;margin:0px}
.tb_button {padding:1px;cursor:pointer;border-right: 1px solid #8b8b8b;border-left: 1px solid #FFF;border-bottom: 1px solid #fff;}.tb_button.hover {borer:2px outset #def; background-color: #f8f8f8 !important;}.ws_toolbar {z-index:100000} .ws_toolbar .ws_tb_btn {cursor:pointer;border:1px solid #555;padding:3px} .tb_highlight{background-color:yellow} .tb_hide {visibility:hidden} .ws_toolbar img {padding:2px;margin:0px}
At I&I Software, find skilled IT professionals to perfectly suit your needs.
.tb_button {padding:1px;cursor:pointer;border-right: 1px solid #8b8b8b;border-left: 1px solid #FFF;border-bottom: 1px solid #fff;}.tb_button.hover {borer:2px outset #def; background-color: #f8f8f8 !important;}.ws_toolbar {z-index:100000} .ws_toolbar .ws_tb_btn {cursor:pointer;border:1px solid #555;padding:3px} .tb_highlight{background-color:yellow} .tb_hide {visibility:hidden} .ws_toolbar img {padding:2px;margin:0px}